Introduction
La publication de Gemini 3 a inclus un tableau massif montrant les performances du modèle sur dix-neuf benchmarks divers. De tels tableaux sont désormais courants, mais ils créent une situation statistique étrange. Les benchmarks mesurent ostensiblement des aspects différents, mais comme les modèles ont tendance à s'améliorer sur de nombreux benchmarks à la fois, l'ensemble de données des scores de benchmarks est dominé par une seule dimension de "Capacité Générale".
Dans cet article, je vais décrire les statistiques de cet ensemble de données, examiner ce qui reste lorsqu'on élimine cette dimension dominante (indice : c'est la "Claudiness"), et discuter de la manière dont cela se rapporte à une question importante sur la généralisation cross-task.
Points clés de l'analyse :
- •Une seule dimension explique environ 50% de la variance des scores sur 39 benchmarks
- •L'Epoch Capabilities Index (ECI) prédit les scores avec un R² = 0.91
- •Une deuxième composante capture une dimension "Claudiness" liée aux modèles Anthropic
- •Cette analyse soulève des questions sur les limites de la généralisation entre tâches
I. Les Données de Benchmarking Sont Dominées par une Seule Dimension
C'est l'une des leçons de notre récent travail sur l'Epoch Capabilities Index (ECI), qui combine trente-neuf benchmarks en un score de capacités unique. Si les benchmarks n'étaient généralement pas corrélés entre eux, on s'attendrait à voir de grands résidus : les scores de benchmarks prédits par le nombre ECI d'un modèle ne correspondraient pas aux scores de benchmarks réels du modèle.
Il s'avère que nous observons une très bonne correspondance. En d'autres termes, notre ensemble de données nominalement à haute dimension est bien approximé par une seule dimension.
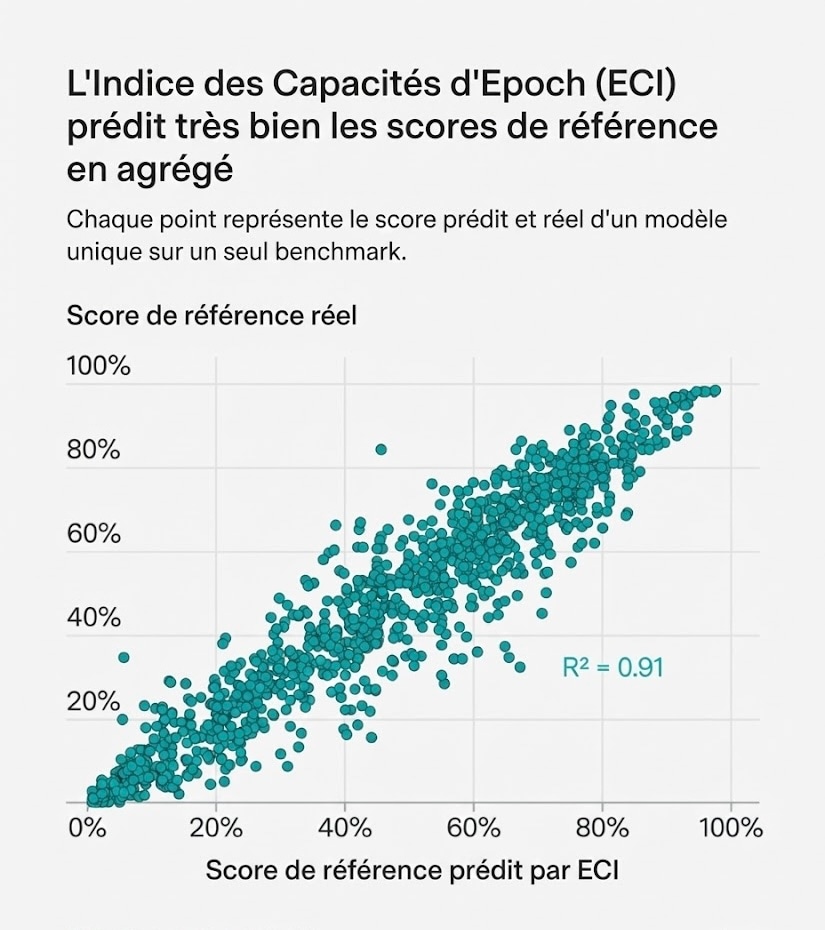
Figure 1 : L'Indice des Capacités d'Epoch (ECI) prédit très bien les scores de référence en agrégé. Chaque point représente le score prédit et réel d'un modèle unique sur un seul benchmark.
II. Analyse en Composantes Principales (PCA)
Pour aller au-delà de cette dimension, nous pouvons effectuer une Analyse en Composantes Principales (PCA). Cela pose essentiellement la question : si nous créons des "composantes" synthétiques en prenant des sommes pondérées des différents scores de benchmarks, quelle est la variance maximale dans l'ensemble de données que nous pouvons expliquer avec le moins de composantes possible ?
Lorsque nous appliquons cela aux données brutes sous-jacentes à l'ECI, la première composante capture environ la moitié de la variance de l'ensemble de données. Le tableau ci-dessous montre les pondérations des différents benchmarks dans cette composante, représentant 80% du poids total.
Notez que les poids sont tous positifs et peu dispersés. C'est-à-dire que la PCA trouve également une composante unique de "capacité générale".
Pondérations de la 1ère Composante Principale
| Benchmark | Poids |
|---|---|
| GPQA diamond | 0.30 |
| Aider polyglot | 0.29 |
| OTIS Mock AIME 2024-2025 | 0.28 |
| LiveBench | 0.27 |
| SimpleBench | 0.27 |
| Balrog | 0.27 |
| WeirdML | 0.26 |
| FrontierMath Tiers 1-3 | 0.25 |
| CadEval | 0.24 |
| SWE-bench Verified | 0.23 |
| GSO-Bench | 0.22 |
| FrontierMath Tier 4 | 0.19 |
Ces 12 benchmarks représentent plus de 80% du poids total de la première composante principale.
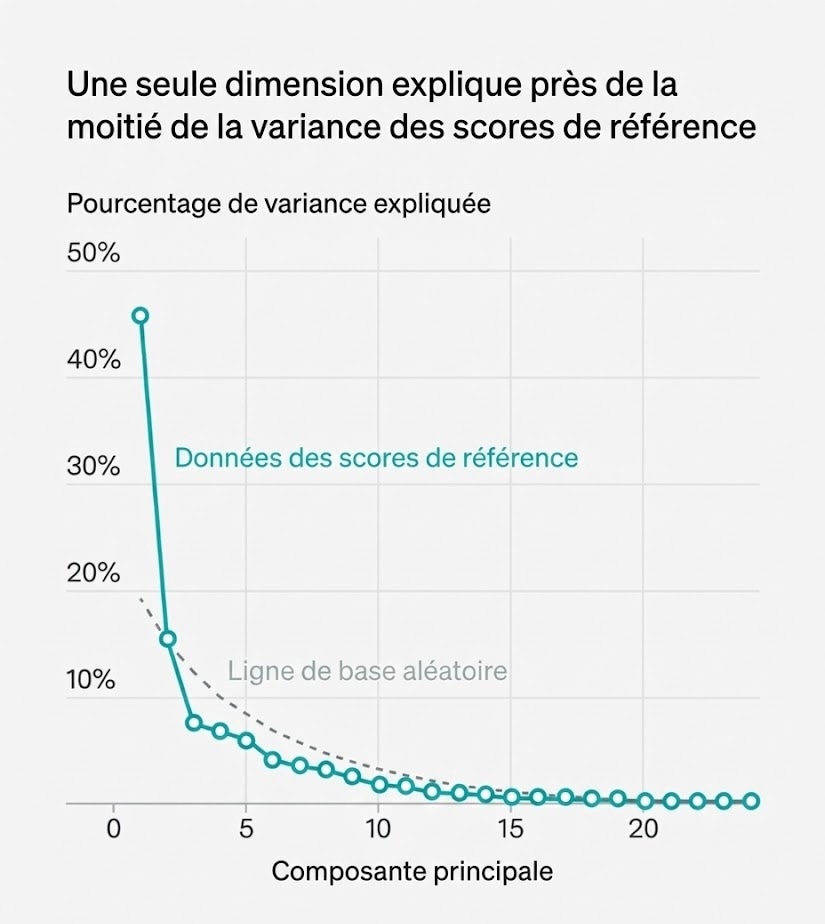
Figure 2 : Une seule dimension explique près de la moitié de la variance des scores de référence. Le graphique montre la magnitude de toutes les composantes principales, comparée à la taille des composantes trouvées dans des données aléatoires de même forme.
III. Les Données Montrent une Dimension "Claudiness" Plus Petite
Quelle est cette deuxième composante ? Voici les poids principaux, par valeur absolue, que cette composante attribue aux benchmarks, représentant à nouveau plus de 80% du poids total.
Par construction, cette composante est orthogonale à la composante principale de "capacité générale". Quand j'ai vu cela pour la première fois, j'ai dit que cela ressemblait à quelque chose comme "bon aux tâches agentiques, mais mauvais en vision... et aussi mauvais en mathématiques ?"
Mais je l'ai montré à un collègue et il a simplement dit "c'est Claude". Il avait raison.
Pondérations de la 2ème Composante Principale
| Benchmark | Poids | Interprétation |
|---|---|---|
| The Agent Company | +0.42 | Tâches agentiques ✓ |
| OSUniverse | +0.37 | Systèmes d'exploitation ✓ |
| VideoMME | -0.35 | Vision multimodale ✗ |
| OSWorld | +0.35 | Interactions OS ✓ |
| Factorio Learning Environment | +0.33 | Jeux de stratégie ✓ |
| VPCT | -0.28 | Vision ✗ |
| FrontierMath Tier 4 | -0.26 | Mathématiques avancées ✗ |
Valeurs positives (vert) = points forts de Claude. Valeurs négatives (rouge) = points faibles relatifs.
Voici les cinq meilleurs modèles sur cette composante, ainsi que les cinq moins bons :
Les Plus "Claude-y"
| Modèle |
|---|
| Claude Sonnet 3.5 (Oct '24) |
| Claude Sonnet 3.5 (Jun '24) |
| Claude Sonnet 3.7 |
| Claude Sonnet 4 |
| Claude Opus 4 |
Les Moins "Claude-y"
| Modèle |
|---|
| GPT-5 |
| GPT-4o-mini |
| GPT-4o (Nov '24) |
| GPT-4o (Aug '24) |
| o4-mini |
Je pense que cette deuxième composante montre que les benchmarks ne sont pas entièrement de la "capacité générale" plus du "bruit", même si c'est une assez bonne approximation. Bien que cette deuxième composante ne soit pas statistiquement significative, je pense qu'il est juste de dire qu'elle s'aligne avec la perception publique générale des priorités d'Anthropic, c'est-à-dire qu'ils semblent fabriquer Claude ainsi intentionnellement.
Cela a mis à jour ma réflexion sur une question plus large, comme je vais l'expliquer ensuite.
IV. La Dimension "Capacité Générale" Est-Elle Profonde ou Contingente ?
La grande question est pourquoi une seule dimension capture tant de variance dans les scores de benchmarks. Je peux penser à deux raisons possibles, correspondant à deux mondes possibles dans lesquels nous pourrions être. J'appellerai ces mondes "profond" et "contingent".
📘 Le Monde "Profond"
Dans le monde "profond", il existe une capacité sous-jacente unique qui régit la performance des modèles sur des tâches superficiellement non liées. Dans ce monde, la seule chose qu'un développeur de modèle peut faire est d'augmenter cette capacité. S'ils réussissent, leur modèle devient meilleur en tout.
C'est un monde où la généralisation cross-task est profonde et intrinsèque.
📙 Le Monde "Contingent"
Dans le monde "contingent", il existe de nombreuses capacités orthogonales que les modèles peuvent avoir. Elles sont orthogonales dans le sens où les développeurs de modèles doivent faire un travail complètement différent pour qu'un modèle s'améliore sur chaque capacité.
Cependant, dans le monde que j'imagine, les clients demandent des modèles avec de nombreuses capacités, et donc les développeurs font l'effort de réaliser cela. La corrélation observée est donc contingente à l'effort de développement, pas une loi fondamentale.
Quel Monde Ressemble le Plus au Nôtre ?
Parfois dans l'histoire de l'IA, les choses ont ressemblé au monde contingent. AlphaGo était surhumain au go mais c'était absurde de lui demander de faire quoi que ce soit d'autre.
À d'autres moments, les choses ont ressemblé au monde profond. Quand les LLMs commençaient à monter en puissance, la prédiction du token suivant sur du texte web relativement non organisé balayait des tâches NLP qui avaient auparavant été dominées par des modèles spécialisés.
Première approximation : Les scores de benchmarks semblent identiques dans les deux mondes.
Mais l'existence de la dimension "Claudiness" me semble être un peu de preuve pour le monde "contingent". Anthropic s'est concentré sur la création de modèles qui sont à la pointe du codage agentique. Sans investissement supplémentaire ciblé, les modèles s'avèrent ne pas être exceptionnels en mathématiques avancées.
Il y a sûrement une certaine généralisation entre les tâches, mais peut-être est-ce un signe de ses limites.
V. Une Question à un Trillion de Dollars
La dimension Claudiness n'est pas une preuve très forte pour le point de vue contingent. Une preuve plus forte pourrait être la manière dont les développeurs de modèles investissent massivement dans la collecte de données spécialisées, comme les environnements d'apprentissage par renforcement (RL) pour des verticales industrielles.
Même ainsi, il est possible qu'ils fassent cela et que le RL montre une excellente généralisation cross-task.
Comment Tester Cette Hypothèse ?
Une façon de tester cela serait de trouver un benchmark non contaminé qui mesure quelque chose d'inhabituel, et de voir s'il est corrélé avec la dimension "Capacité Générale". Malheureusement, nous ne savons pas ce qui compte comme "inhabituel" pour les modèles parce que nous ne savons pas ce qu'ils ont vu lors de l'entraînement.
De plus, je soupçonne qu'il y a un effet de sélection où les benchmarks qui montrent les meilleurs modèles avec de mauvais scores ont tendance à attirer l'attention. Pourtant, cela semble valoir la peine d'être poursuivi.
💡 La Question à un Trillion de Dollars
Comme Steve Newman l'a récemment formulé : "jusqu'où peut-on aller en mettant simplement un nombre insensé de choses en distribution" est l'une des questions à un trillion de dollars.
Je doute qu'il y ait des limites en principe à tout mettre en distribution, mais si nous sommes plus dans le monde contingent, alors nous ne devrions pas nous attendre à beaucoup de gains gratuits de la généralisation non plus.
Chaque point de pourcentage d'amélioration sur chaque benchmark devra être payé. Ici, je pense que nous devrions nous attendre à voir les capacités continuer à s'améliorer de manière assez générale, mais seulement tant que le volant de la croissance et de l'investissement continue de permettre aux développeurs de consacrer des ressources à faire activement que cela se produise.
🔮 Implications pour l'Avenir
- →Les progrès continueront tant que les investissements massifs persistent
- →Chaque capacité pourrait nécessiter un effort de développement spécifique
- →La généralisation cross-task a peut-être des limites sous-estimées
- →Les benchmarks futurs pourraient révéler de nouvelles dimensions orthogonales
Notes Méthodologiques
- 1.
Méthodologie : Nous filtrons notre ensemble de données aux benchmarks créés en 2023 et au-delà, et aux modèles avec au moins 8 scores de benchmarks. Nous combinons différents paramètres de raisonnement pour le même modèle, en prenant les scores maximums.
Nous utilisons k-nearest neighbors pour imputer les données manquantes, en transformant les scores [0-1] par un logit d'abord, en pondérant par la distance, et en utilisant 5 voisins. Nous effectuons ensuite la PCA.
- 2.
Ce résultat principal est en accord avec des travaux antérieurs, bien que nous ayons maintenant un ensemble de données de benchmarks beaucoup plus large (39 benchmarks vs ~10 dans les études précédentes).
- 3.
Limite de l'analyse : La "Claudiness" pourrait simplement refléter des choix d'optimisation temporaires plutôt qu'une dimension fondamentale. Des analyses futures avec davantage de modèles de différents développeurs seront nécessaires pour confirmer la robustesse de cette dimension secondaire.
Pass IA : Votre accès privilégié à l'intelligence artificielle
Rejoignez la liste d'attente pour être parmi les premiers à accéder à Pass IA, notre plateforme exclusive qui démocratise l'accès aux modèles d'IA de pointe pour la recherche et l'innovation.
Accès Prioritaire
Soyez parmi les premiers à tester nos outils IA
Modèles de Pointe
Accédez aux derniers modèles d'IA pour vos recherches
Communauté Exclusive
Rejoignez une communauté de chercheurs et innovateurs